Corey Harell has uploaded an excellent writeup on the working of Windows Application Experience and Compatibility features. Here he explains how process entries/traces show up in locations such as the ShimCache and RecentFileCache.bcf. For forensic/malware analysts, this is a great place to search for recent processes that were run.
This post is a logical continuation of Corey's post. In Windows 8, the 'RecentFileCache.bcf' file has been replaced by a registry hive named 'Amcache.hve'. The location of this file is the same as its predecessor:
<DRIVE>\Windows\AppCompat\Programs\Amcache.hve
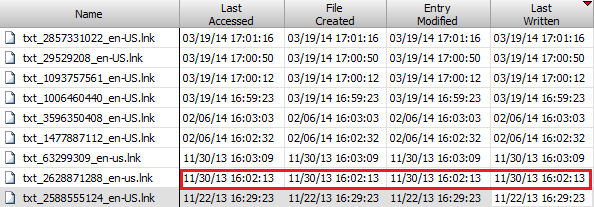
This file stores information about recently run applications/programs. Some of the information found here includes Executable full path, File timestamps (Last Modified & Created), File SHA1 hash, PE Linker Timestamp, some PE header data and File Version information (from Resource section) such as FileVersion, ProductName, CompanyName and Description.
![]()
The Last Modified date on this key may be taken as the first time a particular application was run. I have not seen it change on subsequent runs. Under this key reside several values holding details about that file. Refer the illustration below. This is for a file on a FAT volume on external USB disk.
![]()
Value Names are in hexadecimal and range from 0 to 17 and then two extra entries for 100 and 101 are seen. Here are the descriptions I have been able to decipher so far.
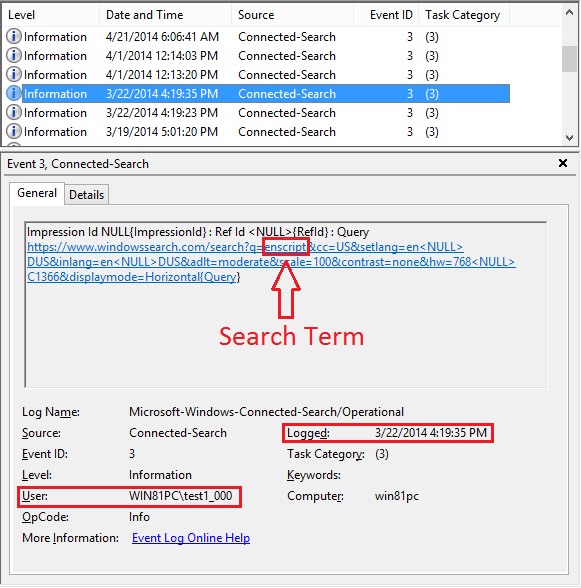
I've written an Enscript to parse out this information to the console. Download here. This is code, not an enpack, so anyone can easily translate to python or perl or another open platform.
It outputs Amcache information as shown below:
File Reference = 03f180
Volume GUID = {8e49b4d2-4d4a-11e3-9717-000c29775430}
First Run Timestamp (Last Modified on key) = 11/15/13 19:48:19
Modified Time 2 = 11/03/13 17:42:39
File path = E:\Fetch.exe
Language Code = 0
PE Header Hash = 01012bb2314b06e59d290d4effbab22e77d7f87ecbeb
File Size = 58880
PE Header SizeOfImage = 77824
PE Header CheckSum = 0x00014D67
PE Header Linker Timestamp = 0x4E8B796E = 10/05/11 02:53:58
Modified Time = 11/03/13 17:42:40
Created Time = 10/04/11 23:23:58
SHA1 hash = 000005b6d3ebc6a5484a270f4f0e04738d1e5a53ee25
The SHA1 hash is a vital bit of information that MS has added, as now we can track malware even if its deleted/wiped itself from the system. Also, since the hive stores data about volume guids and file references, it can also be added to the list of location to review to aid in tracking of USB devices.
This post is a logical continuation of Corey's post. In Windows 8, the 'RecentFileCache.bcf' file has been replaced by a registry hive named 'Amcache.hve'. The location of this file is the same as its predecessor:
<DRIVE>\Windows\AppCompat\Programs\Amcache.hve
This file stores information about recently run applications/programs. Some of the information found here includes Executable full path, File timestamps (Last Modified & Created), File SHA1 hash, PE Linker Timestamp, some PE header data and File Version information (from Resource section) such as FileVersion, ProductName, CompanyName and Description.
The Hive
Amcache is a small hive. Below is a view of the hive loaded in encase. There are only 4 keys under a 'Root' key. (Folders in the registry are called keys). The data of interest to us is located in the 'File' key. Files are grouped by their volume GUIDs. These are the same Volume GUIDs that you can find in the SYSTEM hive under MountedDevices and also under NTUSER.DAT MountPoints2.
File References
Under each volume guid are File Reference keys each representing a single unique file. In case of an NTFS volume, this key name will look something like this: e0000430d. This is the NTFS File Id and sequence number. Here sequence number is 0eand file id is 0000430d. For FAT volumes it is unknown what this value represents.The Last Modified date on this key may be taken as the first time a particular application was run. I have not seen it change on subsequent runs. Under this key reside several values holding details about that file. Refer the illustration below. This is for a file on a FAT volume on external USB disk.

Value Names are in hexadecimal and range from 0 to 17 and then two extra entries for 100 and 101 are seen. Here are the descriptions I have been able to decipher so far.
| Value | Description | Data Type |
| 0 | Product Name | UNICODE string |
| 1 | Company Name | UNICODE string |
| 2 | File version number only | UNICODE string |
| 3 | Language code (1033 for en-US) | DWORD |
| 4 | SwitchBackContext | QWORD |
| 5 | File Version | UNICODE string |
| 6 | File Size (in bytes) | DWORD |
| 7 | PE Header field - SizeOfImage | DWORD |
| 8 | Hash of PE Header (unknown algorithm) | UNICODE string |
| 9 | PE Header field - Checksum | DWORD |
| a | Unknown | QWORD |
| b | Unknown | QWORD |
| c | File Description | UNICODE string |
| d | Unknown, maybe Major & Minor OS version | DWORD |
| f | Linker (Compile time) Timestamp | DWORD - Unix time |
| 10 | Unknown | DWORD |
| 11 | Last Modified Timestamp | FILETIME |
| 12 | Created Timestamp | FILETIME |
| 15 | Full path to file | UNICODE string |
| 16 | Unknown | DWORD |
| 17 | Last Modified Timestamp 2 | FILETIME |
| 100 | Program ID | UNICODE string |
| 101 | SHA1 hash of file | UNICODE string |
I've written an Enscript to parse out this information to the console. Download here. This is code, not an enpack, so anyone can easily translate to python or perl or another open platform.
It outputs Amcache information as shown below:
File Reference = 03f180
Volume GUID = {8e49b4d2-4d4a-11e3-9717-000c29775430}
First Run Timestamp (Last Modified on key) = 11/15/13 19:48:19
Modified Time 2 = 11/03/13 17:42:39
File path = E:\Fetch.exe
Language Code = 0
PE Header Hash = 01012bb2314b06e59d290d4effbab22e77d7f87ecbeb
File Size = 58880
PE Header SizeOfImage = 77824
PE Header CheckSum = 0x00014D67
PE Header Linker Timestamp = 0x4E8B796E = 10/05/11 02:53:58
Modified Time = 11/03/13 17:42:40
Created Time = 10/04/11 23:23:58
SHA1 hash = 000005b6d3ebc6a5484a270f4f0e04738d1e5a53ee25
The Unexplained
There are two Last Modified timestamps (11 and 17). I have noticed that the timestamp in 17 is almost always 1 second behind the timestamp for 11. This is a bit of a mystery, it is probably due to conversion to a DOS timestamp and back.The SHA1 hash is a vital bit of information that MS has added, as now we can track malware even if its deleted/wiped itself from the system. Also, since the hive stores data about volume guids and file references, it can also be added to the list of location to review to aid in tracking of USB devices.