On macOS, the spotlight database is a central database holding metadata of all files/folders that macOS indexes and is always located at the root of any disk under /.Spotlight-V100.
However, while browsing the folders on my macOS 10.14 (Mojave) image, I find a folder that contains yet another spotlight database. It appears that there are now more than one spotlight databases on a single disk. There is one for each user located at:
~/Library/Metadata/CoreSpotlight/index.spotlightV3/
As with the other spotlight database, the files that hold the information are store.db and .store.db.
Mojave (10.14) isn't the first version of macOS to include this database. This appeared first in High Sierra (10.13).
What is in it?
The per-user database store is used to store metadata from items that aren't files or folders. Items seen so far are:
- Safari browser history (web pages visited)
- Safari browser bookmarks
- News App history (web pages visited)
- Notes App notes
- Maps App data (locations?)
- kMDItemRecipientEmailAddresses
- kMDItemPrimaryRecipientEmailAddresses
- kMDItemAdditionalRecipientEmailAddresses
- kMDItemHiddenAdditionalRecipientEmailAddresses
However no email metadata was seen with a single configured IMAP account in the Mail app.
Since this is a test environment with very little activity and almost no apps other than those that come with macOS, there is likely to be a lot more metadata from different apps in this database on real world systems.
Since this is a test environment with very little activity and almost no apps other than those that come with macOS, there is likely to be a lot more metadata from different apps in this database on real world systems.
Why a separate database?
Reading Apple's documentation here and here seems to suggest that this is the implementation of functionality intended to allow app developers to provide in-app content searches and includes the ability to define metadata to do so. Items indexed are not required to be files.
Prior to this (10.12 and below) there existed a folder at
~/Library/Caches/Metadata/Safari/
which housed all the *.webhistory files. See pic below.
 |
| Figure 1 - webhistory files in ~/Library/Caches/Metadata/Safari/ |
The individual files were plists which were then indexed by spotlight.
 |
| Figure 2 - webhistory file content |
That folder now does not exist and in its place we have the new spotlight database.
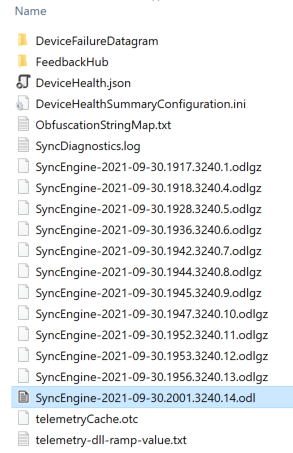
Parsing the data
Using mac_apt's single_plugin script to only run the spotlight plugin over individual store.db files, we can easily parse the database.
 |
| Figure 3 - mac_apt_singleplugin to parse the store.db file |
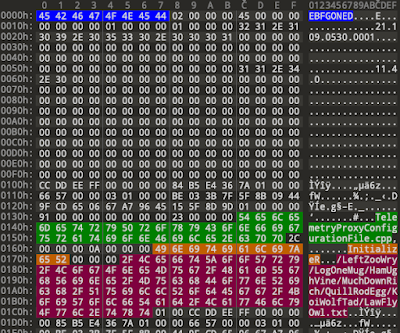
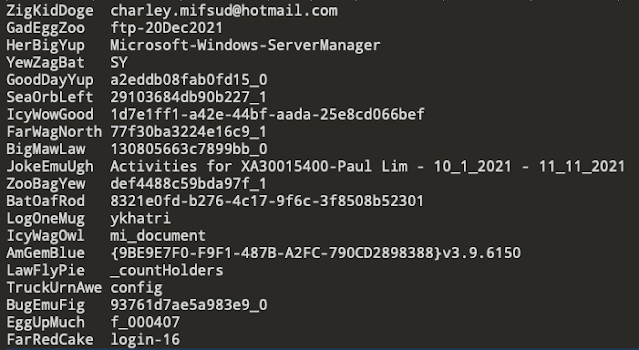
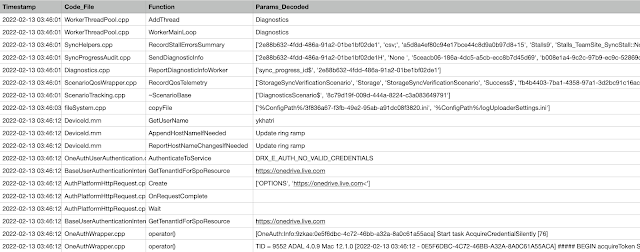
There are quite a few fields, some more important than others. Below are some screenshots showing selected data (notes, safari history, and news). mac_apt gives you the data as a spreadsheet, sqlite db and a flat text file too (similar to mdls output).
 |
| Figure 4 - notes metadata from store.db (not all fields shown here) |
 |
| Figure 5 - safari history from store.db (not all fields shown here) |
 |
| Figure 6 - A single entry from News app showing all metadata (parsed from store.db) |
mac_apt's spotlight plugin has been updated to automatically handle/process these user spotlight databases now.